More Signal, Less Noise: Visualping's Road Ahead for Data Science
By Emily Fenton
Updated July 7, 2021

How we are using machine learning to reduce false positives
Who likes fire drills? You work in a high rise downtown office and everyone is asked to leave and meet at an assigned gathering area on the street. If your office is on the 52nd floor, which means slogging down 52 floors by foot. A rainy day will make a fire drill miserable. Fire drills have a purpose but they always come at the worst possible time, when you are busy.
So the answer is, nobody, absolutely nobody, likes fire drills.
At Visualping, we feel the same about false alerts. They are like fire drills: they happen from time to time and they happen for a good reason. False alerts notify you that something changed on the pages that you are tracking, but that change is simply not relevant to your business case. If they happen too often, they can erode part of the productivity you and your team gain from automation services like Visualping.
The Web is a constantly evolving ecosystem built atop layers of highly complex interacting systems that can lead to unpredictable behaviour. Changes to websites have accelerated as more and more human and business activity happens online. As a result we are continuously improving our systems to differentiate between relevant and noisy changes. The needs of our corporate clients have also increased in scope. Visualping has users in 85% of Fortune 500 companies with some customers relying on our services for monitoring tens of thousands of pages. For those users, minimizing false alerts improves the efficiency of their downstream workflows and thus reduces operational costs.
Our original product has evolved over the years to reduce false alerts; including heuristic interventions to block page elements like ads, social media counters, and dynamic content that are changing, but are not important for our users. Until today, identifying an intervention strategy for specific pages has been a manual process. Finding a way to identify and block these elements automatically is where our developments in machine learning have started.
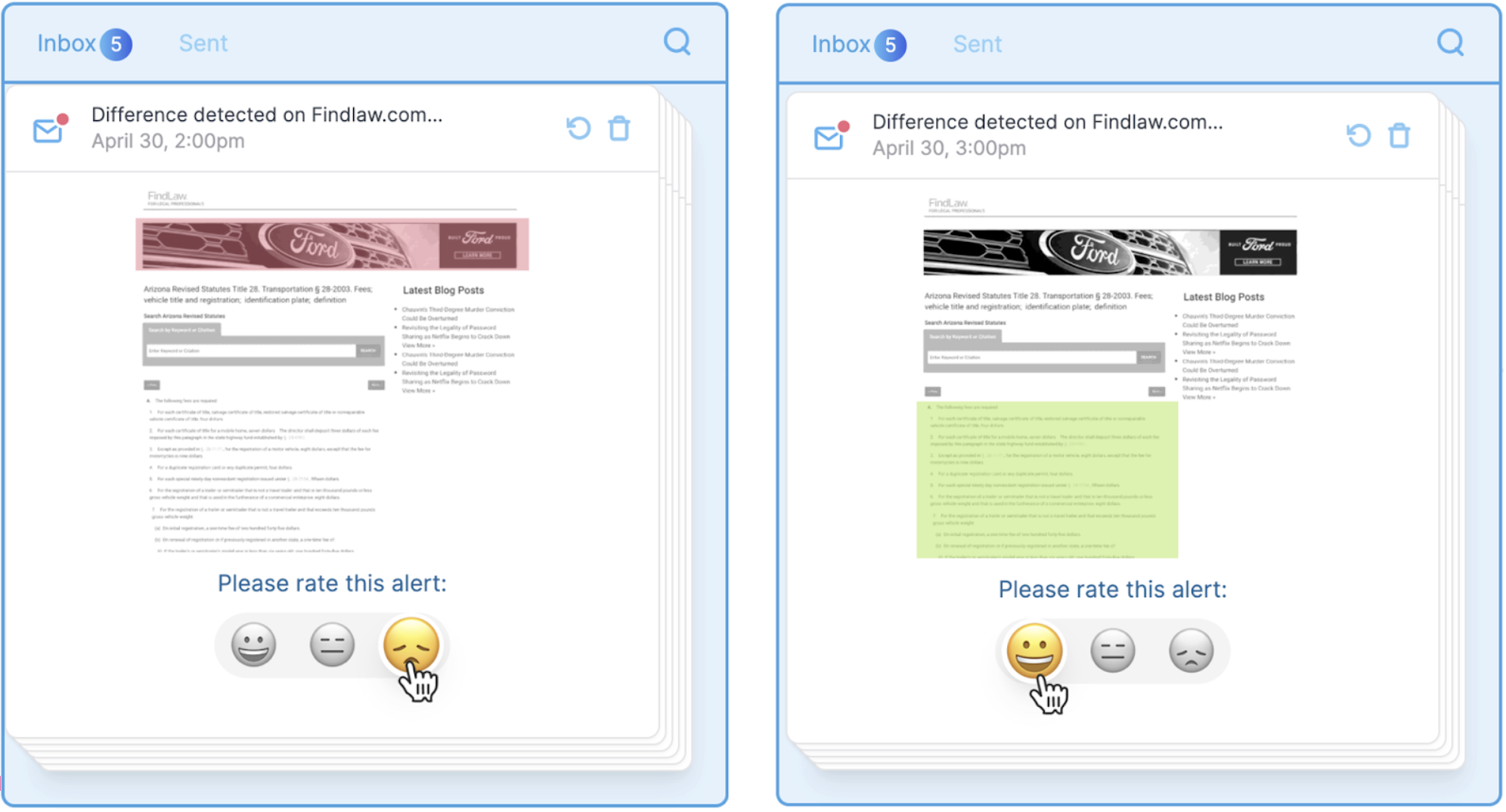 We now allow users to directly train Visualping’s worker bots (the crawlers visiting pages to check for changes on their behalf) in the simplest possible way. With just one click on the email alerts received, users can rank the quality of the alert: good, neutral or bad. Our algorithms will identify consistent patterns by comparing this feedback with element-level changes on the page to evolve a strategy for effective change detection, without the noise.
We now allow users to directly train Visualping’s worker bots (the crawlers visiting pages to check for changes on their behalf) in the simplest possible way. With just one click on the email alerts received, users can rank the quality of the alert: good, neutral or bad. Our algorithms will identify consistent patterns by comparing this feedback with element-level changes on the page to evolve a strategy for effective change detection, without the noise.
Machine learning at every level
We are particularly excited about this new direction and the substantial investment in training models to bring greater flexibility and automation to our core crawler stack. It is our crawl workers that mediate Visualping’s interaction with the Web and conduct crawls on behalf of our customers. We think about it as bringing the next generation of adaptive behaviour to the cutting edge of crawl technology with the aim of evolving our crawl workers to be more intelligent agents on the Web and make use of user feedback to adjust crawler parameters when visiting a Web property to ensure that the content is correctly parsed and meaningful to the intention driving that visit.
This is where Visualping is really set up to succeed. We can leverage our scale to combine feedback across users with similar target pages in order to improve the parameters of our crawlers and propose optimal settings for those users as they create new jobs. The feedback loop between our customers and the systems driving our crawlers will allow us to create an ever evolving, large-scale, human-annotated dataset. It’s every ML scientist’s pipe dream!
Alongside the launch of Visualping for Business in the fall, we’ll also be deploying a reinforcement learning model that helps choose optimization strategies to ensure a high rate of success when accessing, parsing, and reporting meaningful changes on candidate Web properties. This new feature set is fueled by our aforementioned feedback mechanism, which allows users to provide quick feedback any time a change is reported.
Webscale intelligence and web data maintenance
Another exciting trend is the increased evolution of specific and trending use cases that our customers have revealed to us within our own product. The flexibility of Visualping means that often we are surprised by a particular application we never thought of. This leads to a growing corpus of related use cases that will fuel many business intelligence applications and cost saving automations for the modern enterprise.
One of the most common commercial applications of our system is web-data maintenance: our users have collected large databases of information but that information continuously changes. Visualping change alerts allows those large databases to keep up with the pace of change we see today. Some of our customers are already using our API to automate these interactions and update this data automatically. Alongside the Visualping for business launch we will be releasing a version 2.0 API with additional functionality for users who want to further streamline their change monitoring pipeline.
Another exciting area of opportunity is exploratory and unsupervised analyses. Every data scientist loves a good fishing expedition, especially when building custom tooling to extract meaningful patterns feeds directly into potential business intelligence services. If a commercial user is interested in a specific set of changes online, chances are other businesses are as well. We are currently prototyping graph theoretical representations of our customer jobs corpus to better leverage the volume and diversity of our use cases to provide strategic insight into web properties most important and most actively related to particular domains of interests.
This is a really exciting machine learning problem, and the quality of our offerings in the space are set up to scale alongside their utilization! This is where I imagine we’ll be increasing our investment and focus as business use cases make up a larger proportion of our crawl job volume.
Still lots to look forward to in 2021
Behind these exciting feature developments, there is a crazy amount of work to do and the dev team is buzzing with energy. For my part, I’m excited to be building a data science dream team from scratch and busy with getting the foundation right.
Any ML pipeline can only ever be as good as the data assets at our disposal. That’s why we’re focussing on measuring the right things, and measuring them the right way. From revamping our data collection instrumentation to establishing rigorous and nimble experimentation processes, we are reinventing the relationship with our data assets to achieve the “more signal, less noise” mantra.
We are eager to deploy the next generation of ML-powered features across the board, in our internal-facing systems to keep things running smoothly and reliably, and in our intelligence offerings to help turn the goldmine of user stories our customers share with us everyday into exciting new insights into ever changing modern Web.
(title photo credit: Markus Spiske - Unsplash)
Want to monitor web pages for changes?
Sign up with Visualping to get notified of alerts from anywhere online, so you can save time, while staying in the know.
Emily Fenton
Emily is the Product Marketing Manager at Visualping. She has a degree in English Literature and a Masters in Management. When she’s not researching and writing about all things Visualping, she loves exploring new restaurants, playing guitar and petting her cats