Best Web Scraping Tools in 2026: Complete Comparison Guide
By The Visualping Team
Updated July 3, 2026

Last updated: July 2026
Somewhere on the web right now, a competitor is editing a pricing page, a supplier is revising a spec sheet, and a regulator is posting new guidance. Web scraping tools exist so nobody on your team has to catch those changes by hitting refresh.
This guide compares nine tools that keep showing up in real evaluations: Bright Data, Oxylabs, Apify, Zyte, Decodo (the company formerly known as Smartproxy), Octoparse, Diffbot, Firecrawl, and ParseHub. They are less interchangeable than most listicles admit. Some are bulk scraping infrastructure. Some are developer platforms. One is an AI extraction engine, and one is a free desktop app beloved by grad students. Because our own product comes up in this category constantly, we close with an honest note on where Visualping fits: it does a different job entirely (watching specific pages, alerting you the moment something changes, and handling structured data extraction as a managed service for Solutions customers), and we'd rather say that plainly than pretend it's a bulk scraper.
One quick note on the legal side before you scrape anything: check the website's terms of service, respect robots.txt, and stay compliant with data protection laws like GDPR and CCPA. The Computer Fraud and Abuse Act (CFAA) sets the ground rules in the U.S., and similar laws exist worldwide.
The tools at a glance
| Tool | Best for | Pricing model | Standout limitation |
|---|---|---|---|
| Bright Data | Enterprise data collection on hard targets | Free tier (5K records/mo); pay-as-you-go $1.50/1K records; plans from $499/mo | Pricing complexity; overkill for small jobs |
| Oxylabs | Bulk data collection at enterprise scale | Subscription, starts around $49/mo | Developer-only; overkill for small jobs |
| Apify | Developer platform with thousands of pre-built scrapers | Free ($5 credits/mo); paid from $29/mo | Credit model takes forecasting effort |
| Zyte | Per-request scraping API from the Scrapy team | Pay-as-you-go, from ~$0.13/1K simple requests | Developer-first; costs vary by site difficulty |
| Decodo (formerly Smartproxy) | SEO and SERP data through proxy networks | Subscription, starts around $50/mo | API-first; custom targets take setup work |
| Octoparse | No-code bulk scraping with a visual builder | Free plan; Standard from $69/mo (annual) | Proxy/CAPTCHA usage billed on top |
| Diffbot | AI-powered extraction and knowledge graphs | Premium, starts around $299/mo | Pricing excludes smaller teams |
| Firecrawl | Clean web data for AI agents and LLM pipelines | Free (1K credits/mo); paid from $16/mo | Young product; credits burn fast on heavy modes |
| ParseHub | Free, local, point-and-click scraping | Free tier; paid upgrades | Desktop-bound; struggles on protected sites |
| Visualping | Change monitoring and alerts, not bulk scraping | Free plan (150 checks, 5 cloud pages/mo); Business $100/mo | Not built for million-page bulk crawls |
Jump to a tool: Bright Data · Oxylabs · Apify · Zyte · Decodo · Octoparse · Diffbot · Firecrawl · ParseHub · Where Visualping fits
What is web scraping?
Web scraping is teaching software to collect information from websites automatically. Instead of copying and pasting by hand, a scraper processes hundreds or thousands of pages, pulls out the fields you care about, and packages them as CSV, JSON, or rows in your database.
Modern tools have come a long way from the fragile scripts of a decade ago. A good scraper targets exact data points using CSS or XPath selectors (just the prices, just the contact info), runs on a schedule without supervision, and turns ugly raw HTML into a spreadsheet a human can actually read. The better ones handle scale too, whether that means one page checked every hour or a million pages crawled once.
Why businesses need web scraping tools
Collecting data efficiently is the easy half. The value shows up when someone on your team acts on that data the same day it changes.
Market intelligence and competitive monitoring
Recent research published in the Journal of Business Research found that firms in competitive markets closely track rivals' announcements, acquisitions, and stock market reactions to make faster strategic decisions. Two executives quoted in the study put it bluntly:
"In this fiercely competitive and fast-changing market, as soon as a competitor gains new advantages through an acquisition, we're at risk. It's a dangerous signal; it shows our edge is under threat, and we must react swiftly or face erosion of market share, or worse, being edged out entirely." - Head of Brand and PR, BYD
"We closely monitor our rivals' M&A moves and remain on high alert. An acquisition can mean they are acquiring advanced technologies or unique resources we lack, potentially outpacing us in innovation and market position." - Head of Marketing, Geely
Companies run web scrapers against competitor pricing pages, product launches, press releases, and strategic announcements for exactly this reason: the team that notices first gets to react first.
Lead generation
Finding potential customers is slow, repetitive work. Scrapers pull contact information, company details, and prospect data from directories and professional networks, so the pipeline builds itself while your reps sleep. (Mind the privacy laws here; more on that below.)
Price monitoring
Track competitor prices across thousands of products automatically. McKinsey research found that getting pricing right can boost margins by 2 to 7%. The demand is visible in our own data: of roughly 1.7 million active monitors we sampled on Visualping, our AI classifies about 248,000 as pricing-and-availability pages. Watching prices is one of the most common things people point automated tools at, and there is a whole category of competitor price tracking tools built for it.
Content aggregation
Media companies and content platforms use scraping to pull together news, reviews, and social data. It's how a twelve-person newsroom covers a beat that used to need a hundred.
Research and analysis
Academics, data scientists, and market researchers use scraping to build datasets for studies, train models, or analyze market trends at scale. A market research project that takes weeks by hand takes a scraper an afternoon, with better consistency.
How to choose the right web scraping tool
Picking a web scraper is a fit question, and the honest answers matter more than the feature grids.
1. Technical skill level
Be honest about your team's technical chops. No-code tools give you a visual interface: point, click, select what you want. Low-code tools add custom scripting for the tricky cases. Developer tools (APIs and libraries) offer maximum flexibility but assume someone writes and maintains actual code. A tool your team can't operate is shelfware at any price.
2. Scale requirements
How many pages, how often, and for how long? The answer is usually smaller than teams expect. In a sample of about 2,600 business workspaces on Visualping, the median team watches 13 pages. The heavy tail is real though: 714 of those teams monitor 50 or more pages, and 459 monitor 100 plus. Buy for the pages you'll actually watch this quarter, with headroom, rather than for a hypothetical million-page crawl.
3. Website complexity
Modern websites fight back. JavaScript-heavy sites load content dynamically, so you need a scraper that renders pages the way a browser does. Login walls take special handling. CAPTCHAs and rate limiting will stall naive scripts. And dynamic layouts break brittle selectors, usually the week after you stop checking.
4. Integration requirements
Where does the data need to land? Maybe you need API access to feed your own application, Google Sheets integration for analysis, database connections for the warehouse, or webhook notifications for real-time alerts. A scraper that outputs a CSV nobody opens is a hobby, not a pipeline.
5. Budget considerations
Tools range from free to thousands per month. Weigh per-page pricing against unlimited models, add support and maintenance costs, and count the hours you'd spend building a custom solution. Then compare all of it against the cost of doing the work manually, which is the number that usually settles the argument.
Best web scraping tools for 2026: detailed comparison
1. Bright Data
What it does best: Enterprise web data collection backed by one of the industry's largest proxy infrastructures Perfect for: Data teams that need high success rates on hard targets, at any volume
Bright Data is the incumbent heavyweight of this category, with a residential proxy network the company reports at over 400 million monthly IPs across 195 countries, and a product line that covers the whole spectrum: raw proxies, a Web Unlocker that handles CAPTCHAs and anti-bot systems, pre-built scraper APIs for hundreds of popular sites (Amazon products, LinkedIn profiles, and the like), and ready-made datasets if you'd rather skip scraping entirely. Requests render in full browsers, retries and IP rotation are automatic, and you pay only for successful deliveries.
The typical Bright Data customer is a data, pricing, or research team whose targets actively resist scraping. If a site blocks everything else you've tried, this is usually where the evaluation ends.
What it costs: The Web Scraper API has a free tier of 5,000 records per month, pay-as-you-go runs $1.50 per 1,000 records, and committed plans start at $499/month. Proxy products are priced separately by bandwidth.
The trade-offs are the flip side of the breadth: the product catalog and pricing structure take real effort to navigate, and for a team that just needs a few hundred pages watched, it's far more machinery than the job requires.
Docs: Bright Data documentation
2. Oxylabs
What it does best: Enterprise data collection at massive scale Perfect for: Engineering teams running large-scale collection who need proxies and high success rates
Oxylabs is built for the big leagues: scraping APIs backed by a proxy network of over 100 million IPs. If your first question about a scraping tool is "how many requests per second," you are probably an Oxylabs customer. The proxy pool means requests keep succeeding across geographies, CAPTCHAs get solved automatically, and JavaScript-heavy targets render in managed headless browsers.
Typical workloads: fraud detection that needs real-time verification, compliance monitoring across global markets, large-scale market research, and ad verification or brand protection programs that check what users in 40 countries actually see.
What it costs: Entry pricing starts around $49/month, and enterprise pricing scales with request volume. There is a free one-week trial.
The trade-off is the learning curve. Everything is an API. There is no point-and-click mode, so a developer owns the integration from day one, and the bill grows with ambition. For a team that just needs to watch a few hundred pages, it's a freight train ticket for a trip to the corner store.
Docs: Oxylabs API documentation
3. Apify
What it does best: A full scraping platform with a marketplace of thousands of ready-made scrapers Perfect for: Developers and automation teams who want infrastructure without building it all
Apify sits somewhere between "buy a tool" and "build your own." Its marketplace of pre-built scrapers (called Actors) covers thousands of sites and use cases, so common jobs (scrape Google Maps listings, pull Instagram posts, collect TikTok data) run without writing a line of code. When you outgrow the marketplace, the platform runs your own scrapers in the cloud with scheduling, storage, proxies, and webhooks handled for you, and the underlying open-source library, Crawlee, is a well-regarded foundation if you want to write serious crawlers yourself.
What it costs: The free plan includes $5 in platform credits each month, which covers small recurring jobs. Paid plans start at $29/month (Starter) and scale up to $999/month (Business), with usage measured in compute units on top of the included allowance. Residential proxy bandwidth bills separately, at $8/GB on most plans.
The credit model is the main thing to watch: costs depend on how much memory and runtime your scrapers consume, so budgeting takes a benchmark run rather than a glance at a price sheet.
Docs: Apify documentation
4. Zyte
What it does best: A single API that prices each website by how hard it is to scrape Perfect for: Engineering teams that want predictable per-request costs, and anyone already using Scrapy
Zyte is the company behind Scrapy, one of the most widely used open-source crawling frameworks in production today. Its commercial product, the Zyte API, takes a refreshingly transparent approach: every website is assigned a difficulty tier, and you pay per 1,000 successful responses at that tier's rate. The API automatically picks the cheapest technique that works (plain HTTP where possible, full browser rendering with anti-ban handling where necessary), so you're not paying for a headless browser on pages that don't need one.
What it costs: Pay-as-you-go starts around $0.13 per 1,000 responses for simple sites over plain HTTP, rising with site difficulty and browser rendering. New accounts get $5 in free credit, and monthly commitments earn volume discounts.
This is a developer product through and through: no visual builder, and costs on hard, browser-rendered targets can run an order of magnitude above the headline rate. For Scrapy shops, though, it's the path of least resistance.
Docs: Zyte API documentation
5. Decodo

What it does best: Proxy-based scraping for SEO and marketing data Perfect for: SEO professionals and agencies collecting SERP and social data
Smartproxy rebranded as Decodo in 2025, but the offering is the same shape: proxy services combined with scraping APIs, aimed squarely at SEO professionals and digital marketing agencies. The SERP scrapers pull data from Google and Bing, pre-built e-commerce scrapers cover the major shopping platforms, and the proxy pool (65 million+ residential, datacenter, and mobile IPs across 195+ locations) supports localized collection, which matters when rankings differ city by city.
Agencies use it for rank tracking, keyword research, social media monitoring, price intelligence, and ad verification across regions.
What it costs: Pricing starts around $50/month, with a free trial that includes a few thousand requests. Costs scale with request volume and proxy type.
The catch mirrors Oxylabs: this is an API-first product, so implementation is a developer task, and anything outside the pre-built SEO and e-commerce templates takes real setup work. If your data needs live inside search results pages, though, few tools are as purpose-built.
Documentation: Smartproxy help center
6. Octoparse
What it does best: No-code bulk scraping with a genuinely capable visual builder Perfect for: Non-technical teams that need real scraping volume without engineers
Octoparse is one of the best-known names in visual, no-code scraping at meaningful scale. You point and click your way through a page, and the builder handles pagination, infinite scroll, logins, and dropdowns. A library of 500+ preset templates covers popular sites out of the box, and paid plans run your tasks in the cloud on a schedule with IP rotation and automatic CAPTCHA solving, exporting to Excel, CSV, JSON, and more, with database and Google Sheets delivery on higher tiers.
It occupies a useful middle ground: far more scraping power than a free desktop app, without the developer-only posture of the API platforms above.
What it costs: The free plan allows 10 tasks running locally on your machine. The Standard plan starts at $69/month billed annually (more month-to-month) and adds cloud runs, templates, and anti-blocking. Note that residential proxy bandwidth ($3/GB) bills on usage, on top of the subscription.
The honest caveats: dynamic, aggressively protected sites can still defeat it, and the usage-billed add-ons make real-world costs higher than the sticker price for hard targets.
Get started: Octoparse help center
7. Diffbot
What it does best: AI-powered content understanding Perfect for: Teams building AI systems that need semantic understanding of web content
Diffbot takes a different approach from everything above. Instead of parsing HTML with selectors, its machine learning models read the page: they classify content type automatically (article, product, discussion), pull out entities like people, companies, and prices, and map relationships into knowledge graphs. Point the Analyze API at a URL and it decides what kind of page it's looking at, then extracts accordingly.
That makes it a strong fit for competitive intelligence, content aggregation platforms, and any team building a knowledge base for AI work, especially when the source pages are messy and inconsistent. The knowledge graph demos are impressive; budget a real integration sprint to get the same result on your own data.
What it costs: Plans start around $299/month, firmly premium pricing, with a 14-day free trial.
Two cautions. The price puts it out of reach for smaller teams, and if your data is simple and structured (prices, stock status, table rows), semantic AI extraction is more machinery than the job needs.
Technical docs: Diffbot API overview
8. Firecrawl
What it does best: Turning websites into clean, LLM-ready data for AI agents and pipelines Perfect for: Developers building AI applications that need to read the web
Firecrawl is the breakout tool of the AI-agent era: an open-source-rooted API that takes a URL and returns clean markdown or structured JSON, with the crawling, rendering, and anti-bot handling abstracted away. That output format is the point: it feeds directly into LLM pipelines, RAG systems, and agent frameworks, which is why it has become a go-to choice for teams wiring web data into AI products. Scraping, crawling, and site mapping each cost a predictable one credit per page.
What it costs: The free tier includes 1,000 credits per month. Paid plans run from Hobby at $16/month billed annually (5,000 credits) to Standard at $83/month billed annually (100,000 credits) and up. Advanced modes like structured extraction consume extra credits.
The caveats are those of a young, fast-moving product: features and pricing evolve quickly, and heavy use of extraction or browser-interaction modes burns credits faster than the headline per-page rate suggests. For classic bulk collection against hostile targets, the proxy-network veterans above still have the edge.
9. ParseHub
What it does best: Free desktop scraping Perfect for: Students, researchers, and budget-conscious individuals
ParseHub is a desktop app you download and run locally, with a point-and-click visual builder that handles surprisingly gnarly navigation: pagination, dropdowns, tabs. It exports to CSV, JSON, or Excel, downloads images and files, and can run scheduled jobs. The free tier is the draw here. Graduate students, freelance analysts, and early-stage startups can build and run real scrapers without spending anything.
What it costs: The free plan allows around 200 pages per run with a run-time cap and public projects only; paid tiers raise the limits and add private projects.
The honest assessment for 2026: the desktop app feels dated, runs tie up your machine, and heavily protected sites will shrug it off. The free tier limits also make production business use tough. As a place to learn what scraping can do before spending money, it's still hard to beat, and the documentation and community are solid.
Get started: ParseHub documentation
Where Visualping fits
What it does best: Monitoring specific pages for change and delivering structured, actionable alerts Perfect for: Teams that need to know when pages change (not to bulk-download the web)
Full disclosure: Visualping is our product, and it plays a different position than every tool above. Bulk scraping infrastructure downloads everything on a schedule and leaves you to diff the haystack. Visualping watches the specific pages you care about and pings you when something actually changes, with the change itself extracted and summarized. Across roughly 56 million page checks on our platform over a recent three-month stretch, about 1 in 9 detected a change. A bulk scraper re-downloads the other eight pages anyway; a monitor only interrupts you for the one that moved.
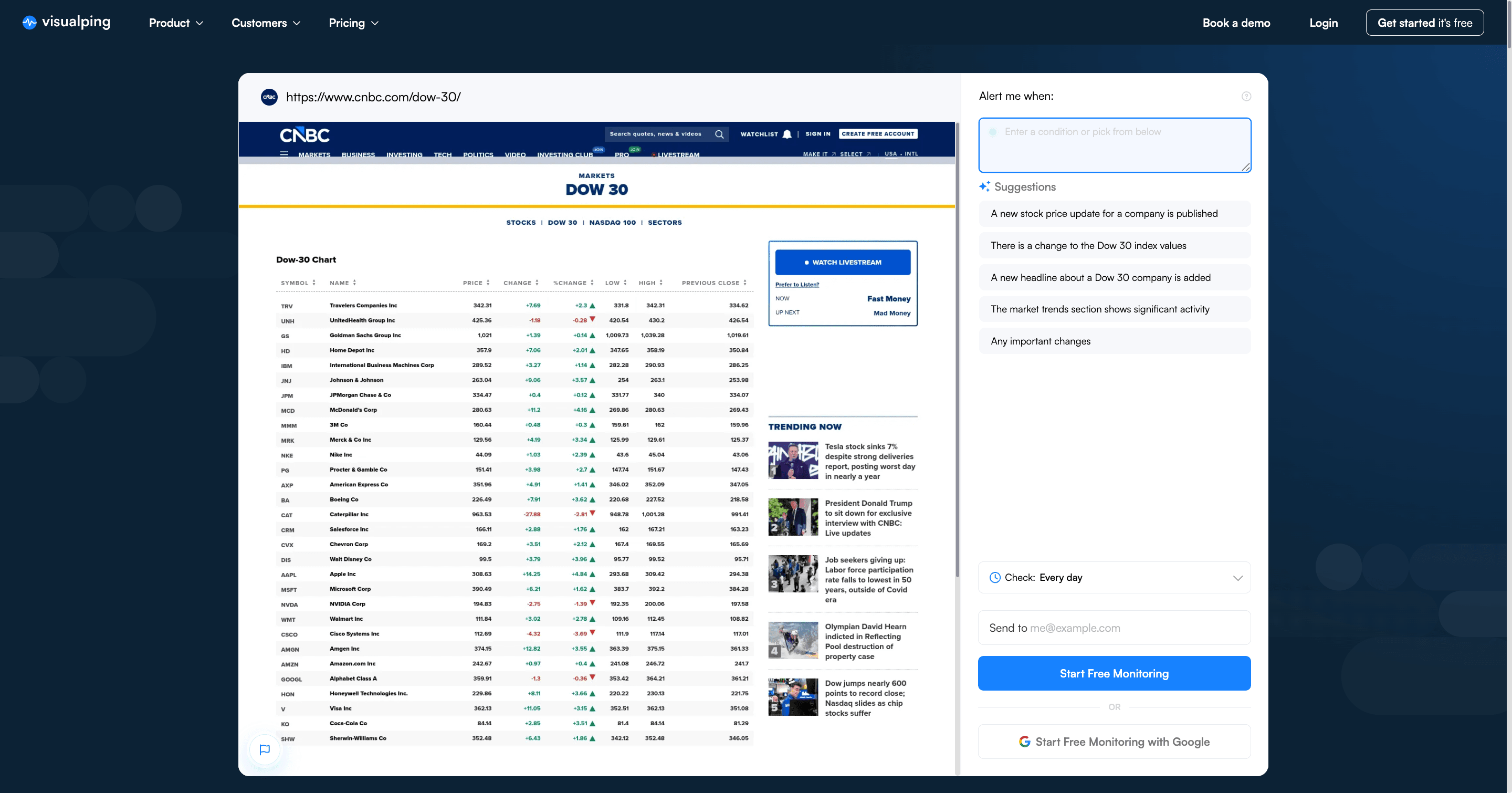
The setup is point and click: highlight the part of a page you want to watch, set a schedule (hourly, daily, or custom), and pick where alerts go. Instead of writing keyword filters, you can describe what matters in plain language, prompts like "Alert me when the price drops below $500" or "Alert me when a new board member is announced." Visualping AI interprets the change against your prompt, and every alert arrives with an AI-written summary plus a binary IMPORTANT flag, so downstream automations can branch on one field instead of parsing a diff.
For developers, every plan (including Free) comes with REST API access and webhooks; API usage draws on your plan's normal check quota rather than a separate metered bucket. That makes monitoring website changes via API viable without an enterprise contract. There is also an MCP endpoint at visualping.io/mcp/sse, so AI agents can create and query monitors directly. That path is already in use: in one active sample, 315 monitors were created through MCP agent integrations rather than by a human in a browser.
For teams that need change data as structured, queryable fields (competitive intelligence programs, compliance teams, data pipelines), structured data extraction is delivered on Solutions plans, where our team builds and manages the extraction setup for you, and data can flow straight into Google Sheets, webhooks, or your own systems.
What it costs: The Free plan includes 150 checks and 5 cloud-monitored pages per month, plus unlimited local monitors that run in your browser. Personal plans start at $10/month. Business is $100/month for 20,000 checks, 200 pages, and 5 users, and Solutions plans (from $3,000/year) add custom volumes, managed setup, and structured data extraction.
Where it wins: Non-technical teams run it without help. Alerts are structured (summary + IMPORTANT flag) instead of raw diffs. Webhooks and API on every plan mean it plugs into whatever you already run. It handles JavaScript-heavy pages because it renders them like a browser.
Where it doesn't: If the job is crawling millions of pages into a data lake, that is bulk-scraper territory, and you should look at Bright Data or Oxylabs above. Complex authentication scenarios sometimes need help from support.
Getting started: Create a free account and put your first five pages under watch in a few minutes.
Feature comparison matrix
| Tool | Ease of use | No-code interface | API access | Free tier | Best for |
|---|---|---|---|---|---|
| Bright Data | ★★★☆☆ | Partial (pre-built scrapers) | Yes | 5K records/mo | Enterprise data collection |
| Oxylabs | ★★★☆☆ | No | Yes | Trial | Enterprise bulk scraping |
| Apify | ★★★★☆ | Partial (marketplace Actors) | Yes | $5 credits/mo | Developers & automation |
| Zyte | ★★★☆☆ | No | Yes | $5 credit | Scrapy teams, per-request pricing |
| Decodo | ★★★☆☆ | Limited | Yes | Trial | SEO/marketing data |
| Octoparse | ★★★★☆ | Yes | Limited | Yes (local runs) | No-code bulk scraping |
| Diffbot | ★★★☆☆ | No | Yes | Trial | AI & knowledge graphs |
| Firecrawl | ★★★★☆ | No | Yes | 1K credits/mo | AI agents & LLM pipelines |
| ParseHub | ★★★★☆ | Yes | Limited | Yes | Students & learning |
| Visualping | ★★★★★ | Yes | Yes (all plans) | Yes (5 cloud pages/mo + unlimited local) | Change monitoring & alerts |
Advanced web scraping considerations
Legal and ethical guidelines
Doing web scraping the right way means following both legal rules and ethical standards.
Start with robots.txt, the file that tells you which parts of a site allow automated access (Google's robots.txt guide explains the format). Then read the terms of service: many websites explicitly ban automated collection, and breaking those terms can create liability under contract law or the CFAA.
Beyond the letter of the law, don't overwhelm servers. Responsible scrapers put reasonable delays between requests, usually one or two per second at most. If you collect information about people, GDPR and CCPA apply, and data minimization is your friend: collect only what you actually need. And when you publish scraped data, credit the original sources where it makes sense.
Want the case law? The hiQ Labs vs. LinkedIn case set important precedents about scraping public web data.
Technical implementation best practices
Production scrapers earn their keep in the failure paths. Build in error handling for connection failures, timeouts, and unexpected page layouts, so a bad night doesn't lose data. Validate what you extract: check expected types, formats, and ranges, because a scraper that silently returns garbage is worse than one that crashes.
Websites also change out from under you. Monitoring tools like Visualping can watch your target pages and alert you when their structure shifts, so you fix the scraper before the data pipeline silently fills with nulls. Plan for secure storage (retention, backups, access control), and prefer cloud-based scrapers if you expect the workload to grow, since local setups scale with your patience rather than your needs.
Common challenges and solutions
Challenge: Websites change all the time and break my scraper. Solution: Use stable selectors (IDs beat long, brittle CSS paths). Put change detection on the target pages. Keep backup selectors ready.
Challenge: Sites block my automated access. Solution: Use reputable proxy services, respect rate limits, rotate user agents, and pick tools with anti-blocking built in. Bright Data, Oxylabs, and Zyte make this their core business.
Challenge: I can't access JavaScript-rendered content. Solution: Use tools with headless browser rendering. Every tool in this guide handles JavaScript rendering to some degree; the API platforms and Visualping do it automatically.
Challenge: Large-scale scraping gets expensive fast. Solution: Scrape only what you need, cache pages you hit frequently, and schedule jobs off-peak. Or reconsider whether you need bulk scraping at all; if you only care about changes, monitoring is far cheaper per useful datapoint.
Alternative approaches to web scraping
Web scraping is powerful, but it's the wrong hammer for some jobs.
Official APIs beat scraping wherever they exist: structured data, guaranteed stability, clear legal standing. Check for one before building a scraper against any major platform. Data providers sell aggregated datasets, trading money for convenience and legal clarity. RSS feeds still work for tracking new content on news sites and blogs.
And when the question is "did this page change?" rather than "give me everything," website change detection is the efficient answer. There is a full roundup of free website change detection tools if you want to compare that category on its own, and a guide to AI web page monitoring if you want alerts that explain what changed instead of a bare notification.
Conclusion: choosing your web scraping tool
The right tool depends on the actual job.
For enterprise bulk collection against hard targets, Bright Data and Oxylabs bring the proxy infrastructure and success rates the job demands, with Decodo the purpose-built pick when the data lives inside search results pages. For developer teams, Apify's marketplace and Zyte's per-request API cover most builds, and Firecrawl is the default when the destination is an AI pipeline. For no-code scraping at volume, Octoparse leads; for learning on a budget, ParseHub's free tier lets you build real scrapers for nothing. For AI teams that need semantic understanding of messy pages, Diffbot's extraction and knowledge graphs justify the premium.
And if what you actually need is to know when specific pages change, with structured alerts, an AI summary, and extraction handled for you on Solutions plans, that's the job Visualping was built for.
Whether you need competitive intelligence, price monitoring, lead generation, or market research, the tooling in 2026 has made extraction the easy part. The hard part is deciding what deserves your team's attention when it changes.
Ready to start? Create a free Visualping account (150 checks and 5 cloud pages a month, no credit card), or talk to our team about larger monitoring programs.
Frequently asked questions
Is web scraping legal? It depends on what you're scraping, how you're doing it, and what you do with the data. Scraping publicly available data is generally fine, but you need to respect copyright, terms of service, and privacy laws. When in doubt, talk to a lawyer.
Can I scrape any website? Technically, you can scrape most websites. Whether you should is a separate question. Always check robots.txt, terms of service, and relevant laws before you start.
How often should I run scraping jobs? It depends on how fresh your data needs to be and what the target website can handle. For most business uses, daily or weekly scraping gives you current data while staying respectful of server resources. Monitoring workloads typically run hotter, since the point is catching a change within the hour it happens.
What data formats do web scrapers support? Most modern scrapers export to CSV, JSON, XML, and Excel, and many integrate directly with databases or apps through APIs. Visualping offers Google Sheets integration so extracted data lands in a spreadsheet as changes happen.
Do I need programming skills to use web scrapers? Not necessarily. Visual tools like Octoparse, ParseHub, and Visualping don't require coding. Technical knowledge helps with complex scenarios and custom integrations.
How do I handle website changes that break my scraper? Set up monitoring to catch when pages change structure. Tools like Visualping's change detection can alert you when target pages get modified, so you know to update your scraper.
Disclosure: This article talks about Visualping, which is our product, alongside other tools in the space. Visualping is a change monitoring and alerting service, not a bulk scraper, and we've tried to be plain about where each tool, including ours, actually fits.
Want to monitor web changes that impact your business?
Sign up with Visualping to get alerted of important updates, from anywhere online.
The Visualping Team
This guide is provided by Visualping's data extraction team. We have over 10 years of combined experience in web scraping, data engineering, and business intelligence. Our team regularly evaluates web scraping tools and best practices to help businesses make smart technology decisions.